Why
- Tackle real-world MRC(machine reading comprehension) problems.
- Reading comprehension is one of the crucial abilities that machine has to have to acquire knowledge through reading the whole web.
- Most existing MRC dataset are different from real-world.
- Experimental results show there exist big gap between the state-of-the-art baseline systems(Match-LSTM,BiDAF) and human performance.
- MRC: challenging work: ccomprehension,inference and summarization.
What
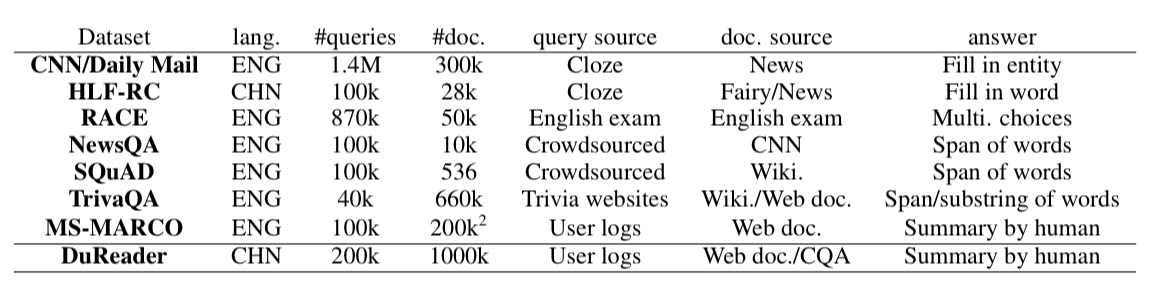
- The largest Chinese MRC dataset so far.
- questions/documents: real application data
answers: human generated - question types: rich annotations.Eg:yes-no/opinion
- answers for each question: multiple
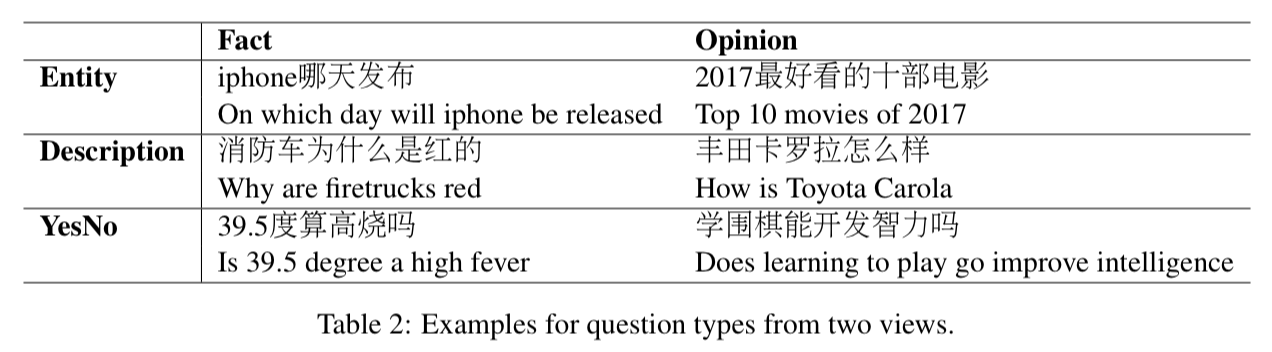
- Sample 1000 questions annotate from two different views:
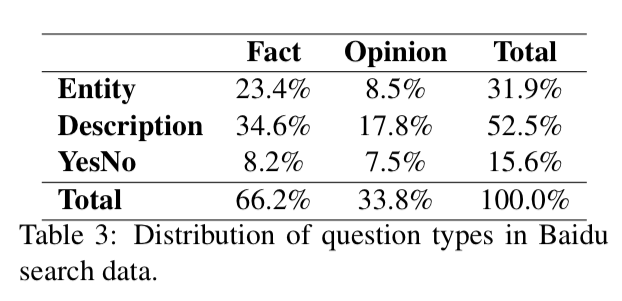
- distribution of the questions in sample data:
Difficulty?
Expriments
- Basic evaluation: BLEU(Paponeni et al.,2002) / Rouge(Lin,2004)
- Match-LSTM(Wang and Jiang,2017)
- BiDAF(Seo et al.,2016): best single model on SQuAD dataset
Set up
word embedding: 300 dimension
hidden vector size: 150 for all layer
Adam algorithm(Kingma and Ba,2014) to train both models
initial learning rate: 0.001
batch size:32
heuristic strategy(启发式策略) is employed to select representative paragraph from each passage
Evaluation
BLEU-4(Papineni et al.,2002) + Rouge-L(Lin, 2004)
Also evaluate the Selected Paragraph system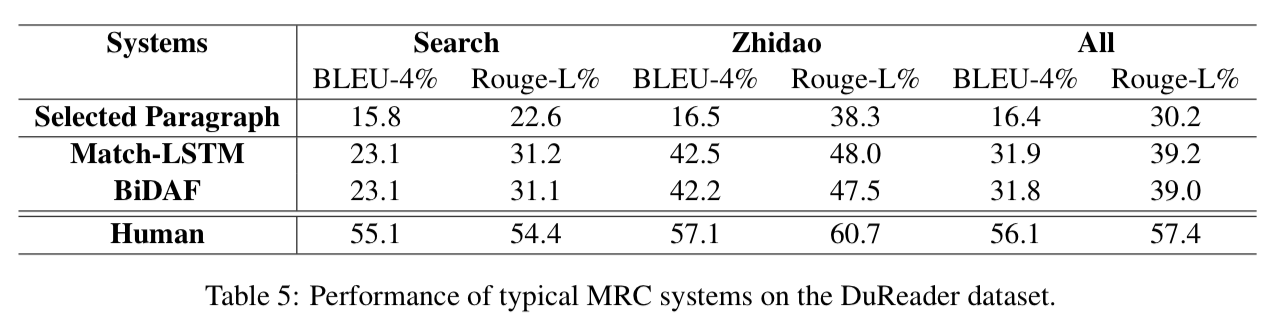
YESNO 问题不适合bleu-4和rouge-l.Propose a novel opinion-aware evaluation method(意见感知评估方法),require not only output an answer in natual language but also give it an opinion label.
Discussion
- 目前的模型把reading comprehension 当成一个span selection任务,但是在DuReader中,人类是通过理解来总结答案的。如何总结或生成答案呢?简单的段落选择策略与黄金段落相比,理解准确度大大降低了,有必要为现实世界的MRC设计新颖高效的全文档表示模型。
- 数据集中一些新特性还没有被广泛研究。yes-no 问题和意见问题需要多文档的MRC.Opinion recognition,cross-sentence reasoning, and multi-document summarization 需要新方法?希望丰富的注释有用。
- 数据集还需要怎样的改进?
Future work
扩大规模,丰富注释(基于反馈)