1. Intro
自然语言处理
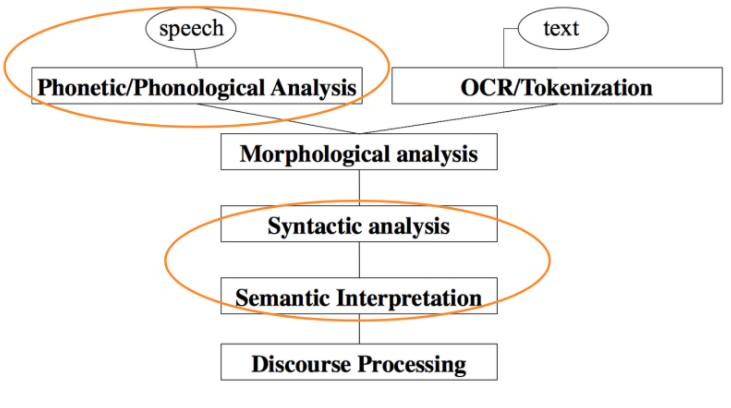
输入: 语音/文本
处理:
- 语音识别+OCR/分词
- 形态学
- 句法分析
- 语义分析
形态学(morphology):形态学(又称“词汇形态学”或“词法”)是语言学的一个分支,研究词的内部结构,包括屈折变化和构词法两个部分。由于词具有语音特征、句法特征和语义特征,形态学处于音位学、句法学和语义学的结合部位,所以形态学是每个语言学家都要关注的一门学科[Matthews,2000]。
这门课主要关注画圈的三个部分,其中中间的两个是重中之重,虽然深度学习在语音识别上的发力最大。
人类语言的特殊之处:
- 自然语言的随机性小而目的性强
- 人类语言是离散的、明确的符号系统。
- 但又允许出现各种变种,比如颜文字,随意的错误拼写“I loooove it”。
- 符号传输到大脑的过程是通过连续的声学光学信号,大脑编码似乎是连续的激活值上的模式。
- 巨大的词表也导致数据稀疏,不利于机器学习。
这构成一种动机,是不是应该用连续的信号而不是离散的符号去处理语言。
深度学习
机器学习:(学习的其实是人类,而不是机器。机器仅仅做了一道数值优化的题目而已)
+ 对专业问题理解非常透彻。
+ 手工设计特征,比如地名和机构名识别的特征模板。
+ 把特征交给某个机器学习算法,比如线性分类器。
+ 机器为这些特征调整找到合适的权值,将误差优化到最小。
深度学习:(表示学习的一部分,用来学习原始输入的多层特征表示)
- 手工特征耗时耗力,还不易拓展
- 自动特征学习快,方便拓展
- 深度学习提供了一种通用的学习框架,可用来表示世界、视觉和语言学信息
- 深度学习既可以无监督学习,也可以监督学习
2. Word2Vec
理解词义
传统:分类词典
- 丢失微妙的差别:adept, expert, good, practiced, proficient, skillful
- 缺少新词
- 主观化
- 需要耗费大量人力去整理
- 无法计算准确的词语相似度
one-hot向量
- 词表大小不同。Google的1TB语料词汇量是1300万,这个向量的确太长了。
- 词语在符号表示上体现不出意义的相似性,比如Dell notebook battery size和Dell laptop battery capacity。而one-hot向量是正交的,无法通过任何运算得到相似度。
Distributional similarity based representations
- 一种用向量直接编码含义的方法
- 通过调整一个单词及其上下文单词的向量,使得根据两个向量可以推测两个词语的相似度;或根据向量可以预测词语的上下文。这种手法也是递归的,根据向量来调整向量,与词典中意项的定义相似。
Word2Vec
待完成 参考word2vec的数学原理