对比
| Dataset | Query | Query source | Doc. | Doc. source | Answer |
|---|---|---|---|---|---|
| SQuAD | 100k | crowdsourced | 536 | Wiki | Span of words |
| DuReader | 200k | user logs | 1000k | Web doc. /CQA | Summary by human |
数据集分析
| dataset | 答案 | 答题逻辑 | 问题 |
|---|---|---|---|
| SQuAD | 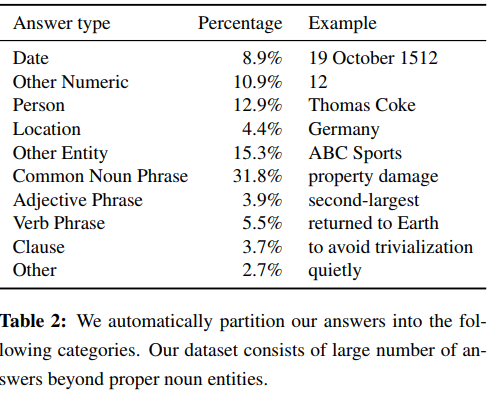 |
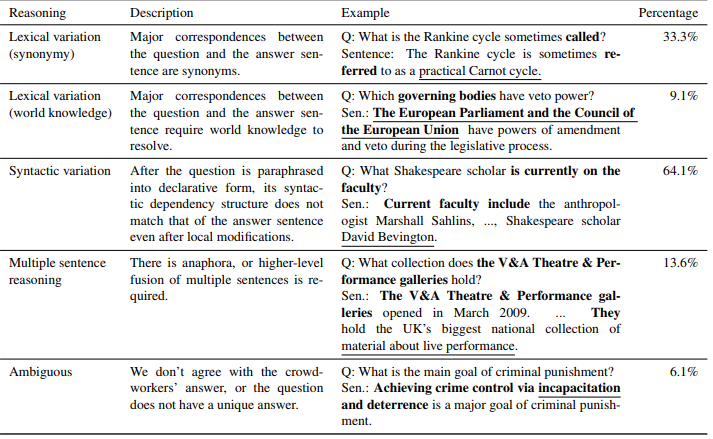 |
|
| DuReader | 每个问题对应的十篇相关网页文档中,5篇来自百度搜索首页的条目,5篇来自百度知道中的用户回答。通过阅读和总结文件,要求用他/她自己的话来回答问题。 |  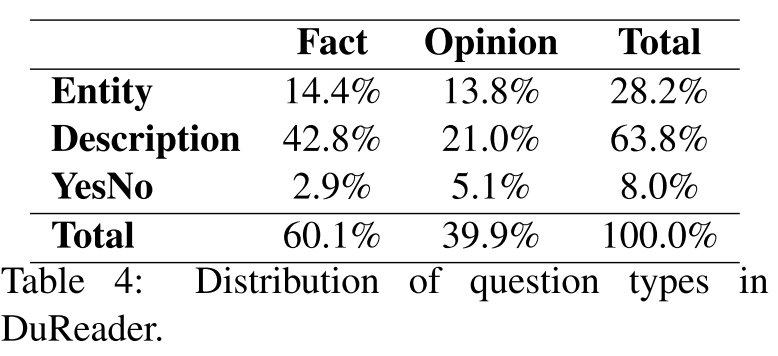 |
|
BiDAF
- BiDAF模型适用于哪些场景的问题?
回答正确的分析: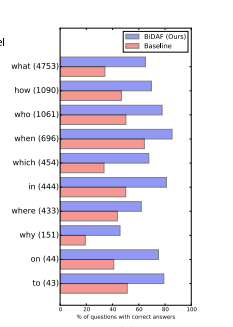
- 错误的分析:
随机选取50个不正确的问题(基于EM),并将它们分为6类。 50%的错误是由于答案的边界不精确造成的,28%涉及语法复杂性和模糊性,14%是复述问题,4%需要外部知识,2%需要多个句子来回答,2%是由于错误符号化。 - 字符级的词嵌入不知道中文环境有木有必要0.0 而且还有把字符和单词向量放到two-layer Highway
Network (Srivastava et al., 2015)上的过程。 - 输出层为查询提供答案。BiDAF模块化特性可以轻松更换输出层,在这里,对输出层进行了修饰,已获得完形填空式的理解。这里要改吧0.0